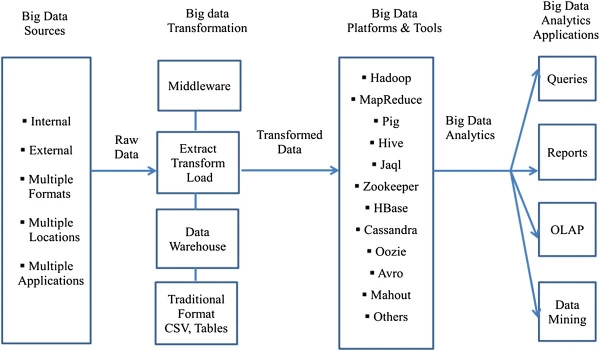
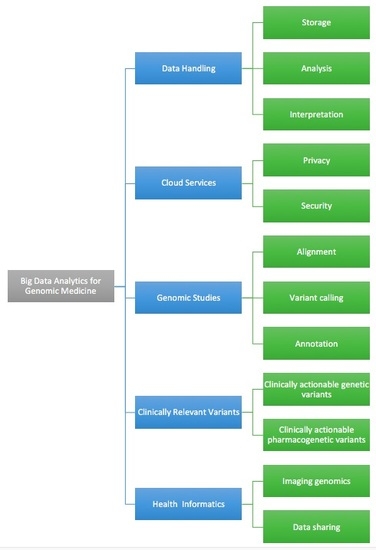
IDC research predicts that the Global Datasphere will grow to 175 Zettabytes by 2025, and China's data sphere is on pace to become the largest in the world. IDC also predicts that Chana's data sphere is expected to grow by 30% of all regions by 2025 (Reinsel, et., 2018).
There are two factors to forecast the future of big data: a rising number of users doing everything online and billions of embedded systems and connected devices collecting and sharing data sets. With such data in the future, experts predict that multi-cloud environments and hybrid environments will come to the forefront of all technologies and businesses (Azhar, 2025). The multi-cloud environment combines public and private cloud computing from more than one cloud system (Seagate.Com, 2022). Multicloud system gives future users access to a combination of private and public data from multiple vendors. Conversely, they can simultaneously access public clouds from multiple vendors combined with the first group of vendors. A hybrid cloud system gives the ability to use one public and one private simultaneously.
The UN 2030 plan on Big Data for Sustainable Development
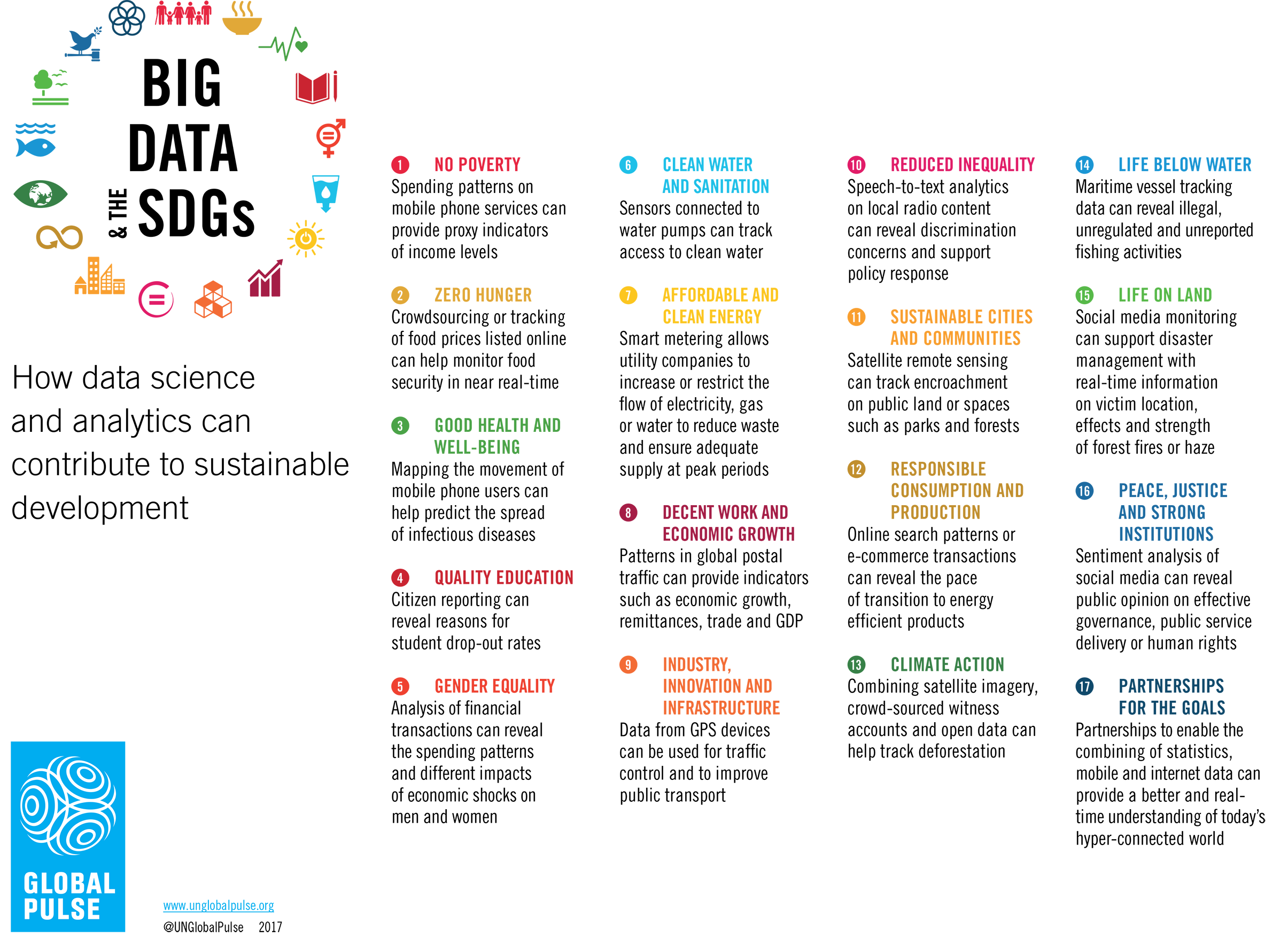
The united nation planned to take advantage of big data for development and humanitarian action by 2030, which is called the Sustainable Development Goals (SDGs) (United Nations, 2022). The Sustainable Development Goals (SDGs) is the global blueprint that calls on all countries to end deprivation, fight inequalities, and tackle climate change, promising that no one is left behind. The analysis shows that they need an integrated action on social, environmental, and economic challenges, focusing on inclusive of no one left behind, to achieve this goal. The following figure shows how data science and analytics can contribute to sustainable development.
Conclusion
We
need to use big data as the most valuable data to help green life,
humanitarians, and public safety for the future. However, it does not
look like the technology is going the right way, as it is made, defined,
and used by giant corporations for more profits. My big concern is not
how much IoT or other devices and social giants get and use information,
but it is how and when Big Data affects climate-related studies and
helps a better and safer life for humans. Climate issues now and
especially in the future require adaptive strategies, actions to incite
social behavior, and the development of regulatory responses to economic
life. Therefore, research in the future should use big data to focus on
understanding the causes of climate change, developing predictive
models, and mitigating solutions (Sebestyén, 2021).
Reference
Azhar, F. (2021, July 20). The Future of Big Data: Predictions from Way2Smile's experts for 2020–2025. Way2smile. Retrieved 2022, from https://www.way2smile.ae/blog/big-data-predictions-for-2020-2025/
Edwards, J. (2021, December 7). What is predictive analytics? Transforming data into future insights. CIO. Retrieved 2022, from https://www.cio.com/article/228901/what-is-predictive-analytics-transforming-data-into-future-insights.html
Leite, M. L., de Loiola Costa, L. S., Cunha, V. A., Kreniski, V., de Oliveira Braga Filho, M., da Cunha, N. B., & Costa, F. F. (2021). Artificial intelligence and the future of life sciences. Drug Discovery Today, 26(11), 2515-2526.
Reinsel, D., Gantz, J., Rydning, J. (2018). From Edge to Core. Retrieved July 28, 2022, from https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf
Kharas, H. A. C. J. L. (2022, March 9). Using big data and artificial intelligence to accelerate global development. Brookings. Retrieved 2022, from https://www.brookings.edu/research/using-big-data-and-artificial-intelligence-to-accelerate-global-development/
Seagate.Com. (2022). Wat is multicloud? | Zakelijke opslag | Seagate Nederland. Seagate.com. Retrieved 2022, from https://www.seagate.com/nl/nl/blog/what-is-multicloud/
Sebestyén,
V., Czvetkó, T., & Abonyi, J. (2021). The Applicability of Big Data
in Climate Change Research: The Importance of System of Systems
Thinking. In Frontiers in Environmental Science (Vol. 9). Frontiers
Media SA. https://doi.org/10.3389/fenvs.2021.619092
United Nations. (2022). Big Data for Sustainable Development. Retrieved 2022, from https://www.un.org/en/global-issues/big-data-for-sustainable-development